Recientemente me fue necesario usar latex para iniciar mi tesis de licenciatura. Para los que no estén familiarizados, latex de acuerdo con wikipedia "es un sistema de composición de textos, orientado a la creación de documentos escritos que presenten una alta calidad tipográfica. Por sus características y posibilidades, es usado de forma especialmente intensa en la generación de artículos y libros científicos que incluyen, entre otros elementos, expresiones matemáticas."
El problema que se me presentó, no sabía cómo compilar mi archivo principal para poder incluir las referencias, el glosario y los acrónimos en el texto.
Busqué por mucho tiempo información en la web, pero sin resultados satisfactorios, finalmente encontré un ejemplo bastante práctico, así que ahora os presento una solución más acertada de lo que estaba buscando en ese entonces.
Modifiqué dicho ejemplo para que aceptara el español, y estos son los pasos a seguir:
En el ejemplo, el editor que usé se llama "Texmaker" desconozco si las funciones con el que este editor cuenta, también la tengan otros editores, he usado también el editor kile, texstudio, lyz, gummi, texworks, y funcionan muy bien. Todos los editores antes mencionados son gratuitos, de modo que los pueden descargar y utilizar libremente:
Aquí también hago uso de la línea de comandos, de tal modo que es necesario usar linux, o al menos que tengan en windows (para usuarios de windows) un emulador de una terminal.
archivo principal:
\documentclass{article}
\usepackage[utf8]{inputenc}
\usepackage{listings}
\makeatletter
\usepackage{times}
\usepackage{setspace}
\usepackage{anysize}
\usepackage{bm}
\usepackage[spanish]{babel}
\usepackage{multirow}
\usepackage{ae}
\usepackage{url}
\usepackage{amsmath}
\usepackage{amsfonts}
\usepackage{color}
\usepackage{amssymb}
\usepackage{graphicx}
\usepackage{latexsym}
\usepackage{epsfig}
\usepackage{multirow}
\usepackage{cite}
\usepackage{apacite}
\usepackage{fancyhdr}
\usepackage{appendix}
\usepackage[acronym]{glossaries}
\makeglossaries
\glossarystyle{altlistgroup}
\include{glosarioacronimos}
\renewcommand{\glossaryname}{Glosario}
\renewcommand{\acronymname}{Acrónimos}
\begin{document}
\title{Cómo crear glosario con lista de acrónimos}
\author{Merino Merino Jesús Fernando}
\date{\today}
\maketitle
%se incluye un archivo en donde estará el cuerpo del texto, así como
%las referencia hacía los acrónimos
\include{temaX}
%Print the glossary
%\printacronyms % not working
\printglossary[type=\acronymtype]
%\printnoidxglossary[type=\acronymtype]
Texto entre la lista de acrónimos y el glosario
%\printglossaries
%\printglossary
\printglossary[title=Glosario,toctitle=Glosario]
\addcontentsline{toc}{section}{Glosario}
\addcontentsline{toc}{section}{Acrónimos}
\bibliographystyle{apacite}
\bibliography{bibliografia}
\end{document}
archivo de referencias llamado bibliografia
@ARTICLE{Alfonso2010a,
author = {M. Alfonso and B. Bernardo and C. Carlos and D. Domingo},
title = {El problema de los gatos y los perros},
journal = {Mascotas},
year = {2010},
volume = {50},
pages = {112-115}
}
@ARTICLE{Alfonso2010b,
author = {M. Alfonso and M. Marta and N. Nuria},
title = {Mi viaje a {EEUU}},
journal = {Revista de viajes},
year = {2010},
volume = {14},
pages = {50-56}
}
@ARTICLE{Patricio2011,
author = {A. Patricio},
title = {Una estrella rosa en el fondo del mar},
journal = {El mar},
year = {2011},
volume = {3},
pages = {1071-1090}
}
@ARTICLE{Zacarias2009,
author = {R. Zacarias and G. Graciela},
title = {?`{C}u\'al te gusta m\'as?},
journal = {Flores},
year = {2009},
volume = {5},
pages = {45-49}
}
@BOOK{Coulouris,
author = {Coulouris, G., and Dollimore, J., and Kindberg, T.},
title = {Sistemas Distribuidos. Conceptos y dise\~no},
publisher= {Pearson Educaci\'on, S. A.},
address = {Madrid},
year = {2001},
edition = {3},
}
@ARTICLE{Oms1,
author = {Centro de prensa},
title = {Obesidad y sobrepeso},
journal = {Organizaci\'on Mundial de la Salud},
year = {2012},
volume = {311},
pages = {1-2}
}
@misc{oms2,
author = {OMS},
title = {Obesidad y sobrepeso},
year = {2014},
url = {http://www.who.int/mediacentre/factsheets/fs311/es/},
note = {[Accesado 5-Octubre-2014]}
}
@misc{wiki:xxx,
author = {Wikipedia},
title = {Redefinición de planeta de 2006 --- Wikipedia{,} La enciclopedia libre},
year = {2010},
url = {http://es.wikipedia.org/w/index.php?title=Redefinici%C3%B3n_de_planeta_de_2006&oldid=32754396},
note = {[Internet; descargado 2-febrero-2010]}
}
@misc{wiki:xx1,
author = {Wikipedia},
title = {Redefinición de planeta de 2006 --- Wikipedia{,} La enciclopedia libre},
year = {2010},
url = \url{http://es.wikipedia.org/w/index.php?title=Redefinici%C3%B3n_de_planeta_de_2006&oldid=32754396},
note = {[Internet; descargado 2-febrero-2010]}
}
@misc{sololapiz,
author = {Jason Brubaker},
title = {Inking a Graphic Novel?},
year = {2010},
howpublished = {\url{http://www.remindblog.com/2010/02/18/inking-graphic-novel/}},
note = {[Accesado 9-Feb-2012]}
}
@misc{webpage1,
author = {Jason Brubaker},
title = {Inking a Graphic Novel?},
year = {2010},
url = {http://www.remindblog.com/2010/02/18/inking-graphic-novel/},
note = {[Accesado 9-Feb-2012]}
}
@ARTICLE{CENETEC,
author = {CENETEC},
title = {Prevenci\'on y diagn\'ostico de sobrepeso y obesidad en ni\~nos y adolescentes en el primer nivel de atenci\'on},
journal = {CENETEC},
year = {2012},
pages = {1-2}
}
archivo con nombre: glosarioacronimos.bib
%Definición de términos
\newglossaryentry{prevalencia}{
name=prevalencia,
description={En epidemiología, proporción de personas que sufren una enfermedad con respecto al total de la población en estudio}
}
\newglossaryentry{maths}{
name=mathematics,
description={Mathematics is what mathematicians do}
}
%Definición de acrónimos
\newacronym{oms}{OMS}{Organización Mundial de la Salud}
\newacronym{cenetec}{CENETEC}{Centro Nacional de Excelencia Tecnológica en Salud}
\newacronym{imss}{IMSS}{Instituto Mexicano del Seguro Social}
\newacronym{issste}{ISSSTE}{Instituto de Seguridad y Servicios Sociales de los Trabajados del Estado}
\newacronym{sedesol}{SEDESOL}{Secretaría de Desarrollo Social}
\newacronym{dof}{DOF}{Diario Oficial de la Federación}
\newacronym{imc}{IMC}{Índice de Masa Corporal}
\newacronym{ensanut}{ENSANUT}{Encuesta Nacional de Salud y Nutrición}
archivo de tema incluido llamado temaX.tex
\section{Sección de referencias}
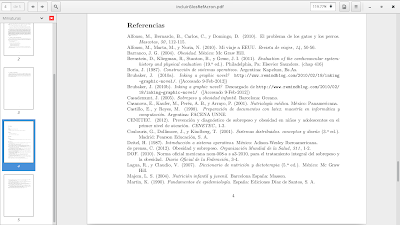
Una referencia se considera al fuente de donde se obtiene información acerca de algo, por ejemplo, podemos citar libros de la siguiente manera, decir, de acuerdo con \cite{Alfonso2010a} la manera de citar correctamente es de este modo.
Las referencias que se mencionen directamente en el texto, son las únicas que aparecen en la sección de bibliografía o referencias. Si se tiene un archivo en donde están todas las entradas bibliográficas, pero si no se hacen referencias directas a ellas, no apareceran en el texto al momento de compilar.
En lo personal, prefiero compilar primero las referencias y después el glosario y los acrónimos, para evitar problemas de referenciados dentro del texto.
La compilación de citas se realiza de la siguiente manera:
\begin{enumerate}
\item Ir a la compilación del archivo principal, seleccionar "BibTex", clic en compilar.
\item Ir de nuevo a la compilación del archivo, seleccionar "Compilación rápida" luego clic en compilar.
\item Realizar los pasos 1 y 2 hasta que en el archivo en la parte final muestre correctamente las referencias.
\end{enumerate}
La compilación de referencias se tiene que realizar cada vez que se agreguen nuevas referencias, si por alguna razón ustedes agregan o modifican datos bibliográficos de una referencia, entonces es necesario volver a compilar el archivo con los pasos anteriores, para que la información de referencias se actualice.
\textbf{Un tip: cuando se considere necesario incluir referencias bibliográficas al final del texto, pero sin hacer mención de dichas citas dentro del texto, realizan lo siguiente, en alguna parte del texto, citen los autores que deseen, luego compilen conforme a los pasos anteriores, después eliminen las citas que previamente había incluido, es decir, las citas que ustedes no mencionan directamente en el texto, pero que sí las quieren agregar en su base de referencias, ahora vuelvan a compilar pero de manera normal, es decir, directamente en "Compilación rápida" sin usar el modo " Bitex, de esa manera se compilan las referencias pero no se hacen mención dentro del texto, al mismo tiempo es incluido dentro de las citas referenciadas al final del documento"}
Ejemplo:
\cite{Alfonso2010a, Alfonso2010b, Patricio2011, Zacarias2009, Coulouris, Jesus, Boria, Castillos, Deitel1, Tanenbaum, Norman, Bernstein, Simel, Oms1, oms2, wiki:xxx, wiki:xx1, sololapiz, webpage1, CENETEC, DOF, MartinK, Majem, Casademunt, Casanova, Barranco, Bonada, Lagua}
\section{Sección con entradas del glosario}
Indicar que una palabra está dada en el glosario, es necesario declarar ahí previamente, es decir, no se puede hacer referencia a una palabra en el glosario que no se haya dado de alta previamente en el archivo del glosario, lo mismo ocurre con los acrónimos.
La compilación de los glosario y acrónimos usando Texmaker se realiza de la siguiente manera:
\begin{enumerate}
\item Ir al menú herramientas
\item Seleccionar la opción "Abrir línea de comandos"
\item Una vez que se abre la consola escribir lo siguiente
\begin{enumerate}
\item pdflatex aquiNombreArchivoPrincipal
\item makeglossaries aquiNombreArchivoPrincipal
\item pdflatex aquiNombreArchivoPrincipal
\end{enumerate}
\end{enumerate}
Después de hacer eso, cierre la consola, y compile el archivo usando la opción "Compilación rápida".
La \Gls{prevalencia} en personas con obesidad y sobrepeso es aterradora. La \glspl{prevalencia} es mínima comparada con la del año anterior.
\section{Sección con acrónimos}
En México instituciones como: La \acrfull{sedesol}, El \acrfull{imss}, El \acrfull{issste}, La Secretaría de Salud, así como el Gobierno Federal, han puesto en marcha diferentes programas para combatir los problemas de obesidad y sobrepeso. Los programas propuestos por estas instituciones básicamente recomiendan dietas, ejercicios físicos, y algunos consejos para mantener el peso en un nivel saludable para la salud.
para compilar los archivos de referencias usar la opción de bibtex varias veces y luego usar la opción compilación rápida
Para compilar los glosarios y acrónimos
hacer lo siguiente desde consola:
pdflatex nombredelarchivoprincipal
makeglossaries aquiNombreArchivoPrincipal
pdflatex nombredelarchivoprincipal
luego compilar en modo compilación rápida y listo
Para descargar el ejemplo completo clic
aquí
 Para descargar el ejemplo completo clic aquí
Para descargar el ejemplo completo clic aquí




 (escrito LaTeX en texto plano)
es un sistema de composición de textos, orientado a la creación de
documentos escritos que presenten una alta calidad tipográfica. Por sus
características y posibilidades, es usado de forma especialmente intensa
en la generación de artículos y libros científicos que incluyen, entre
otros elementos, expresiones matemáticas.
(escrito LaTeX en texto plano)
es un sistema de composición de textos, orientado a la creación de
documentos escritos que presenten una alta calidad tipográfica. Por sus
características y posibilidades, es usado de forma especialmente intensa
en la generación de artículos y libros científicos que incluyen, entre
otros elementos, expresiones matemáticas. , creado por Donald Knuth.
Es muy utilizado para la composición de artículos académicos, tesis y
libros técnicos, dado que la calidad tipográfica de los documentos
realizados con LaTeX es comparable a la de una editorial científica de
primera línea. (
, creado por Donald Knuth.
Es muy utilizado para la composición de artículos académicos, tesis y
libros técnicos, dado que la calidad tipográfica de los documentos
realizados con LaTeX es comparable a la de una editorial científica de
primera línea. (









